
I det föregående blogginlägget beskrev vi hur det gick till när vi tog fram den grundläggande designen för en prototyp på ett generöst användargränssnitt. Nu går vi den första prototypen vi utvecklat och hur vi testat den. Vill du testa den själv så kan du göra det!


Vi hade ju redan tidigare i designfasen valt att utveckla en prototyp avsedd för en viss målgrupp som också delar ett navigeringsfokuserat snarare än sökorienterat beteende: mode- och inredningsdesigners samt andra kreatörer, i t.ex. textil, som söker inspiration för sitt egna skapande.
Prototypen är därför avsedd att stödja ett nyfikenhetsstyrt och lustfyllt gradvis utforskande – via färger och etiketter/taggar – av en samling bilder. Designen är gjord för att vara visuell till sin karaktär och att tillåta användare att snabbt “dyka ner“ bland bilder för att påbörja sitt utforskande. Resultatdisplayen är avsedd att påminna om de sk moodboards, kollage av bilder, som många kreatörer och designers använder som ett stöd i sitt skapande. Vi designade medvetet prototypen att sakna namn, logo eller vara färgsatt på ett sätt som är specifikt för en viss organisation. Detta för att det ska göra det enklare för andra organisationer att sätta sitt varumärke på en egen version av prototypen och utveckla den vidare.
Redan innan vi började koda prototypen, när vi bara hade skisser av prototypen på papper, så började vi systematiskt samla in kvalitativ feedback från användare. Det är långt billigare att ändra i pappersprototyper och i designfasen än i kodnings och utvecklingsfasen!!! Vår analys av användarnas synpunkter resulterade bl.a. att vi gjorde en mycket enklare, och därmed mera användarvänlig, interaktion för användaren att välja färger att filtrera på. Vi hade också idéer om funktioner som vi skulle vilja utveckla men som vi tidigt släppte. De skulle helt enkelt inte rymmas inom tids- och budgetramen. Bland dessa idéer ingick möjligheten för användare att skapa och dela namngivna färgpaletter (”Höst”, ”Glädje”, ”50-tal”) som man också kunde söka matchande innehåll för. Tidigt släppte vi också tanken på en integrerad interaktiv tidslinje. Båda dessa skulle vara intressanta vidareutvecklingsmöjligheter!


Etiketterna och färgerna som användaren kan använda för att utforska de ca 5000 bilderna är extraherade med hjälp av Google Cloud Vision. Etiketterna som föreslås av Google Cloud Vision liknar mer de nyckelord som icke-professionella användare ofta använder i sina sökningar än de officiella sak- och ämnesord som intendenter katalogiserar sina samlingar med. Ibland kallas sådana etiketter för folksonomier och används ofta just när en målgrupp består av icke-specialister. Det finns mycket att skriva om potentialen i att använda AI- och maskininlärningsbaserade bildanalys för att stödja digitisering och digital förmedling av kulturarvssamlingar. Därför kommer vi vid senare tillfälle att skriva ett uppföljningsinlägg om just det ämnet!
Eftersom vi hade fyra medverkande museer i vårt projekt valde vi också att göra ett urval av bilder från deras samlingar. Urvalet, som vi valde skulle omfatta ca 5000 bilder totalt, gjordes på ett sådant sätt att vi skulle få en blandning av modefotografi, konstverk rika på dräktdetaljer, samt bilder på dräkthistoriska föremål och accessoarer. Rent tekniskt gjorde vi urvalet genom att definiera ett antal nyckelord som vi skickade till Europeanas API och laddade ner resultaten (metadata och bildlänkar). Vi valde Europeana då de fyra medverkande museernas samlingar alla finns tillgängliga där och vi därför kunde hämta bilder och beskrivningar från en källa. Detta sparade oss mycket utvecklingstid då vi annars hade behövt utveckla funktionalitet för att hämta innehåll från de tre olika proprietära samlingsförvaltningssystem som de medverkande museerna använder.

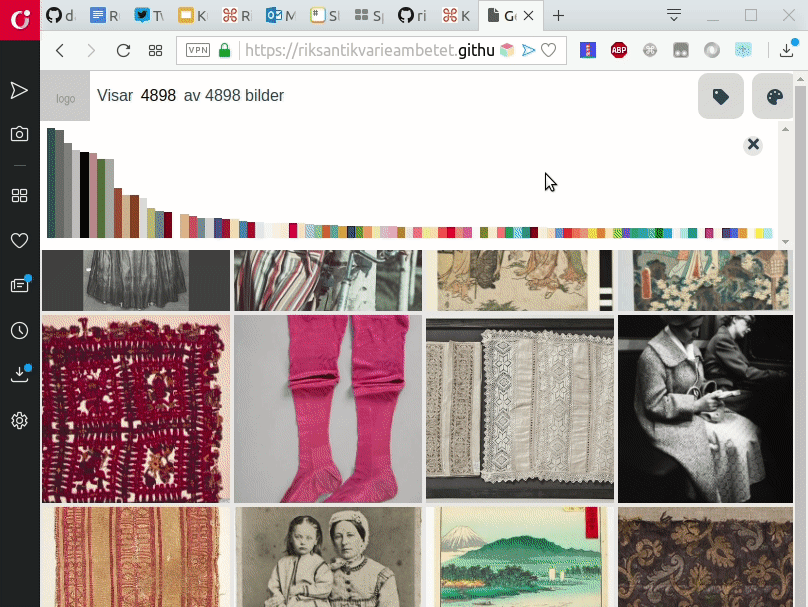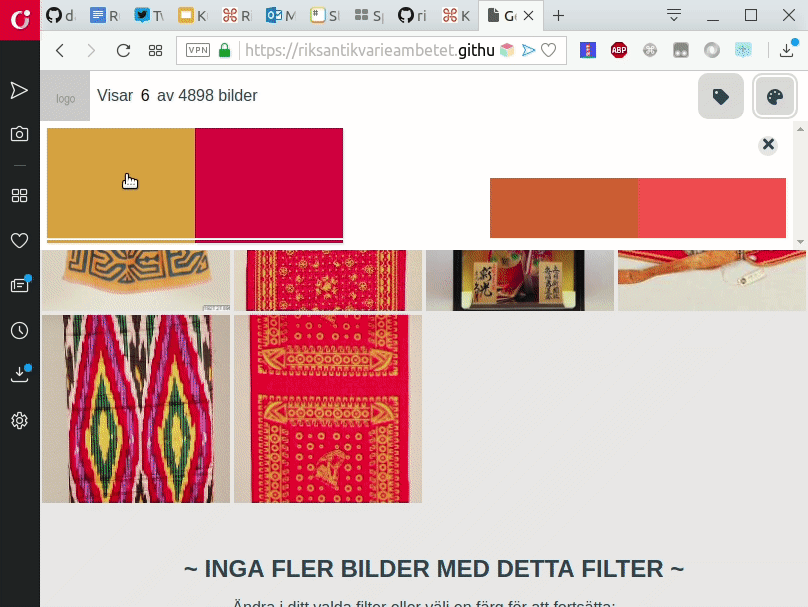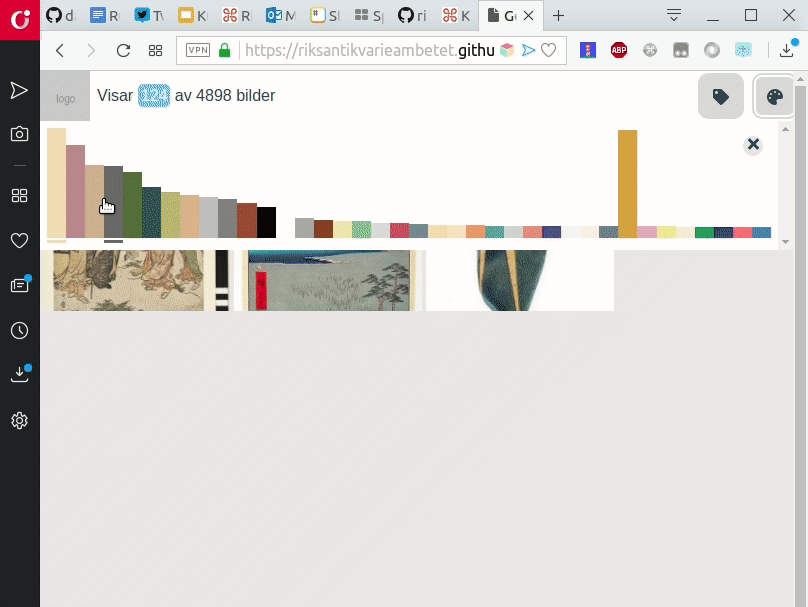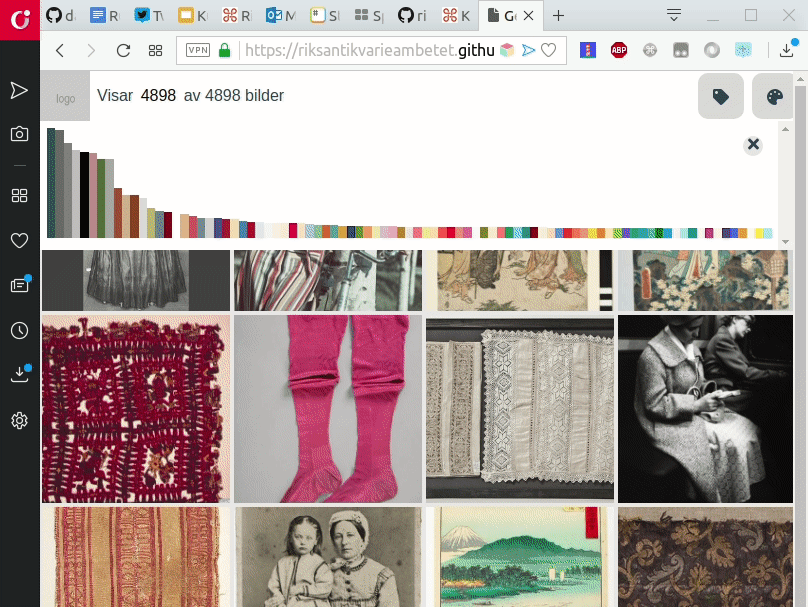
När prototypen först blev funktionell testade vi den med två användare. Detta gav oss ännu mera värdefull feedback, framförallt på användbarhetsproblem, och stärkte oss i vår känsla att vi var på rätt väg, men att vi också behövde göra modifikationer. Efter att vi genomfört dessa gjorde vi ett andra test med två andra testanvändare. Resultaten av våra tester finner du här.
Källkoden och dokumentation finns tillgänglig och är öppet licensierad. Om en institution har sina samlingar i Europeana är det enkelt för en utvecklare att skapa en egen version av prototypen och fylla den med ett annat innehåll än det vi valde. Vi rekommenderar inte att använda prototypen som den är annat än i demo/-testsyfte, men den kan spara dig mycket tid och pengar jämfört med att utveckla ett generöst användargränssnitt själv i från grunden! Om du arbetar för en svensk kulturarvsorganisation och är intresserad av att utveckla en utforskningstjänst i generös stil så ta gärna kontakt med oss!
NB: Prototypen är utvecklad så att den fungerar i moderna webbläsare på mobiltelefoner, läsplattor och laptops/desktops. Den fungerar däremot inte med webbläsaren Internet Explorer.